




글로벌 클라우드 컴퓨팅 시대의 데이터베이스 NewSQL
- OldSQL, NoSQL, 그리고 NewSQL -
클라우드팀 / 한인종, 김경탁
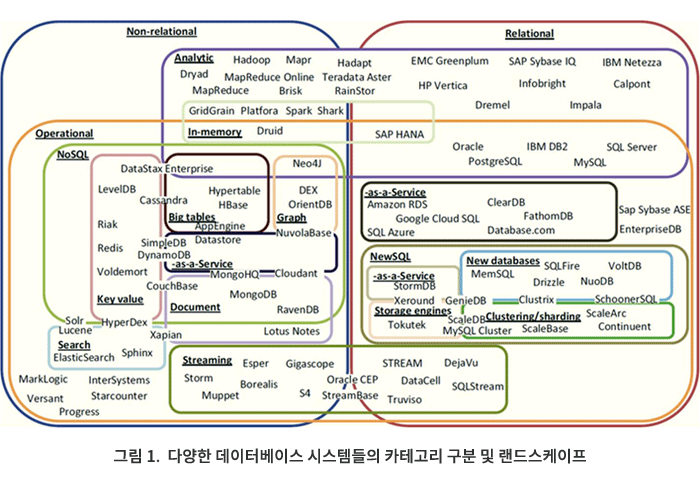
MySQL, 큐브리드, 오라클, 티베로, MariaDB 그리고 PostgreSQL 등 이름이 익숙한 것은 대부분이 OldSQL 즉, 관계형DBMS 입니다. 국가정보자원관리원의 G-클라우드에서 약 900개의 DBMS 인스턴스가 동작하고 있는데 이들 모두 이 관계형DBMS 그룹에 속합니다. 관계형DBMS의 약점은 확장성입니다. 데이터 양이나 트랜잭션 수가 증가하면 더 큰 서버로 업그레이드 하거나, Oracle RAC 또는 Tibero TAC 클러스터에 노드를 추가해야 합니다. 그러나 클러스터에 추가할 수 있는 서버 수에 한계가 있습니다. 관계형 DBMS의 확장 제한 사례
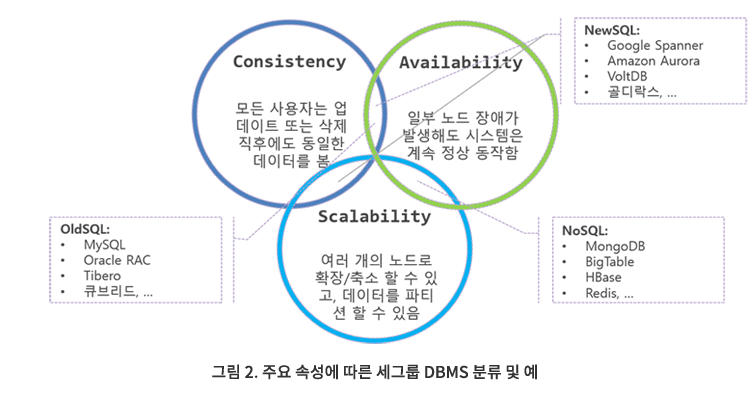
확장성의 한계를 보여주는 좋은 사례가 있습니다. 2000년대 중반에 A통신사는 가입자 증가 추세로 인해 실시간 과금시스템(Billing System)을 확대 구축해야 했습니다. 이 때 DBMS는 익숙한 관계형DBMS만 고려했기 때문에 고성능 대형 서버로 클러스터를 구성하는 것 외에 방법이 없었습니다. 그래서 당시 가장 큰 UNIX 서버였던 HP Superdome 64-Way(CPU 64개) 7대에 Oracle RAC로 클러스터를 구성했습니다. 7대로 구성된 것은 서버를 추가해도 더 이상 트랜잭션 처리량이 증가하지 않았기 때문입니다. 그리고 이 규모의 클러스터 구축 사례가 없었기 때문인지 시험 운영 중에 Oracle RAC에서 전에 없던 유형의 에러들이 여러 차례 발생했고, 결국 오라클사의 DBMS 개발 엔지니어가 한국에서 2~3 개월간 상주하며 버그를 모두 잡았습니다. 이 시스템은 당시 세계에서 가장 크고, 가장 비싼 관계형DBMS 클러스터가 되었습니다. NoSQL - 빅데이터용 DBMS 그룹 스마트폰 사용 확대로 반정형 및 비정형 데이터가 빠르게 증가하며 새로운 유형의 DBMS들이 등장했습니다. 이 DBMS들은 데이터를 저장하는 방식은 제각각(키-값 쌍, 컬럼-패밀리, 문서, 그래프) 이어도 다수의 x86서버 클러스터로 구성되고, 각 서버별로 데이터를 분할하여 유지하며, 데이터는 복제본(보통 세 카피)을 유지하여 일부 서버가 다운되거나 데이터가 손상되어도 데이터베이스 서비스는 중단되지 않는 공통점을 갖고 있습니다. 그리고 데이터가 증가하면 서버를 추가하여 쉽게 확장할 수 있습니다. 페타바이트 규모의 데이터를 다룰 수 있는 확장성과 일부 서버가 다운되어도 데이터에 엑세스 할 수 있는 고가용성이 가장 큰 장점입니다. 그러나 이 그룹에 속하는 DBMS들(Cassandra, MongoDB, H-Base 등)은 관계형DBMS 보다 일관성이 느슨하고, SQL을 지원하지 않습니다. 그래서 NoSQL 이라는 이름이 붙었습니다(4). 이 DBMS들은 ACID 대신 BASE(Basically Available, Soft state, Eventually consistent) 속성을 갖습니다. BASE의 핵심만 간단히 설명하면 데이터베이스 변경 사항은 "최종적으로" 모든 노드에 전파되므로 데이터 쿼리는 업데이트된 데이터를 즉시 반환하지 않거나 정확하지 않은 데이터를 읽을 수 있습니다("오래된 읽기"로 알려진 문제로 일반적으로 몇 밀리 초 이내의 지연이 있습니다). NoSQL에는 트랜잭션과 스키마 개념이 없고, 표준화된 데이터 엑세스 언어인 SQL을 지원하지 않기 때문에(5) 프로그래밍 언어나 각 DBMS 패키지에서 제공하는 툴을 사용해야 합니다. 사용하던 DBMS가 바뀌면? 애플리케이션 코드도 대거 수정해야 합니다. 데이터 저장방식이 다르고, SQL 같은 표준 데이터베이스 엑세스 인터페이스가 없기 때문입니다. UNIX 서버보다 훨씬 저렴한 x86서버에 탑재하고, 데이터가 증가하면 서버 수를 늘려서 쉽게 확장할 수 있지만 금융시스템, 주문처리시스템 같은 애플리케이션들은 트랜잭션 및 일관성 요건을 포기할 수 없기 때문에 NoSQL 카테고리의 DBMS를 사용하지 않습니다. 그래서 NoSQL시스템은 24시간 365일 사용하고, 최종적 일관성으로도 충분한 YouTube(6) 같은 글로벌 서비스를 제공하는 웹 기반 애플리케이션이나 막대한 양의 데이터를 배치(batch) 방식으로 처리하는 빅데이터 분석 플랫폼에서 주로 사용됩니다. 국가정보자원관리원에서 운영하는 빅데이터 분석 플랫폼인 혜안에 NoSQL 카테고리에 속하는 HBase가 포함되어 있지만 현재 사용하지 않고 있습니다. NewSQL - OldSQL과 NoSQL의 장점을 결합 OldSQL 그룹과 NoSQL 그룹 DBMS의 특징을 이해하면 이 둘의 장점을 결합할 수 있을까' 하는 생각이 고개를 듭니다. 이것이 가능하다면 x86서버 여러 대에 데이터베이스를 나누어(파티션 또는 샤드라고 함) 저장하여 페타 바이트 규모의 데이터를 다룰 수 있고, 데이터가 증가하면 서버를 추가하여 쉽게 확장할 수 있으며, 트랜잭션에 대한 ACID 속성을 보장하므로 항상 유효하고 정확한 값을 유지하고, 각 제품에 종속적인 API 대신 표준 SQL을 사용하여 데이터를 손쉽게 다룰 수 있을텐데요. 그런 DBMS가 있을까요? 네, 2006년 경부터 미국의 기업과 대학에서 여러 가지 시도가 계속되었습니다. 그리고 구글과 아마존 같은 탁월한 인력을 보유한 기업들은 직접 개발하여 자사가 사용하고, 클라우드 서비스로 제공하고 있습니다(구글 스패너(Spanner), 아마존 오로라(Aurora)가 그 예).
| 구분 | OldSQL (관계형 DBMS) | NoSQL (빅데이터 용 DBMS) | NewSQL (분산형 RDBMS) |
|---|---|---|---|
| 스키마 | 관계형 스키마 / 테이블 | 스키마 없음 | 둘 다 지원 |
| 확장성 | 읽기 확장성 (scalable read) | 읽기/쓰기 확장성 수평 확장 | 읽기/쓰기 확장성 수평 확장 |
| 고가용성 | 자체 맞춤형 고가용성 | 자동 고가용성 | 빌트인 고가용성 |
| 스토리지 | 디스크 + 캐시 | 디스크 + 캐시 | 메인 메모리 |
| 일관성 | ACID | BASE기반 CAP | ACID |
| OLTP | 부분 지원 (Not Fully Supported) | 지원하지 않음 | 지원 (Fully Supported) |
| 성능 부하 | 매우 큼 | 중간 | 작음 |
| 보안 우려 | 아주 큼 | 낮음 | 낮음 |
| 제품 | Oracle, 티베로, MySQL, PostgreSQL, 큐브리드 | MongoDB, Cassandra, Redis, HBase | VoltDP, Spanner, Aurora, Goldilocks |
| 사례 | 금융, CRM, HR 애플리케이션 | 빅데이터, IoT, 사회관계망 애플리케이션 | 게임, 전자상거래, (고가용성), 통신, 금융 애플리케이션 |
(2) 관계형DBMS는 1970년대 후반에 상용화되었습니다.
(3) SQL은 1970년대 후반에 System R 프로젝트에서 처음 만들어졌습니다.
(4) SQL을 지원하는 DBMS가 몇 종 추가되어 NoSQL을 "Not only" SQL 이라고 해석해야 한다고 주장하기도 합니다.
(5) NoSQL 카테고리에 속하는 DBMS들은 초기에 SQL을 지원하는 것이 없었지만 나중에 2~3 종이 SQL을 지원하게 되었습니다.
(6) YouTube의 동영상에는 이것을 시청한 횟수를 알려주는 'view' 카운트가 있습니다. 이 값이 동기화 되는데 몇 밀리 초 지연되는 "최종적 일관성"이 문제 될 것은 없습니다.
(7) 골디락스라는 NewSQL DBMS를 온라인으로 확장하는 동영상을 YouTube에서 볼 수 있습니다. (https://www.youtube.com/.watch?v=BIRmavP2WnE&t=2506s)